在本文的爬虫实践中将注意力放在网页本身,尝试通过爬虫程序来批量下载HTML网页。之前的爬虫程序一般通过定位网页元素的方法来获取所需要的信息,但因为这里的新任务是下载网页,所以想要获取的信息其实就是整个网页。这里需要将访问得到的网页作为一个HTML保存下来,在这个过程中,通过BeautifulSoup等网页解析工具能够实现对网页信息的高效筛选,去除一些用户并不感兴趣的信息(如广告等)。
01
编写爬虫
新浪财经的个股页面是本次爬取的主要目标,新浪对于某一个股(沪深股市个股)的资讯页面使用类似的网页形式(见图6-1),本节想设计程序爬取某一个股(以其股票代码作为标识)下资讯页面中的所有资讯文章,并将它们保存到本地。

图6-1新浪财经的个股页面
对于这个爬取目标而言在线炒股配资公司,用户不难看出主要需要关注两个步骤:一是访问个股股票代码对应的资讯页面,并通过解析网页的方式获取资讯文章URL地址的列表;二是根据文章URL访问网页并保存其信息。个股资讯文章类似于图6-2。
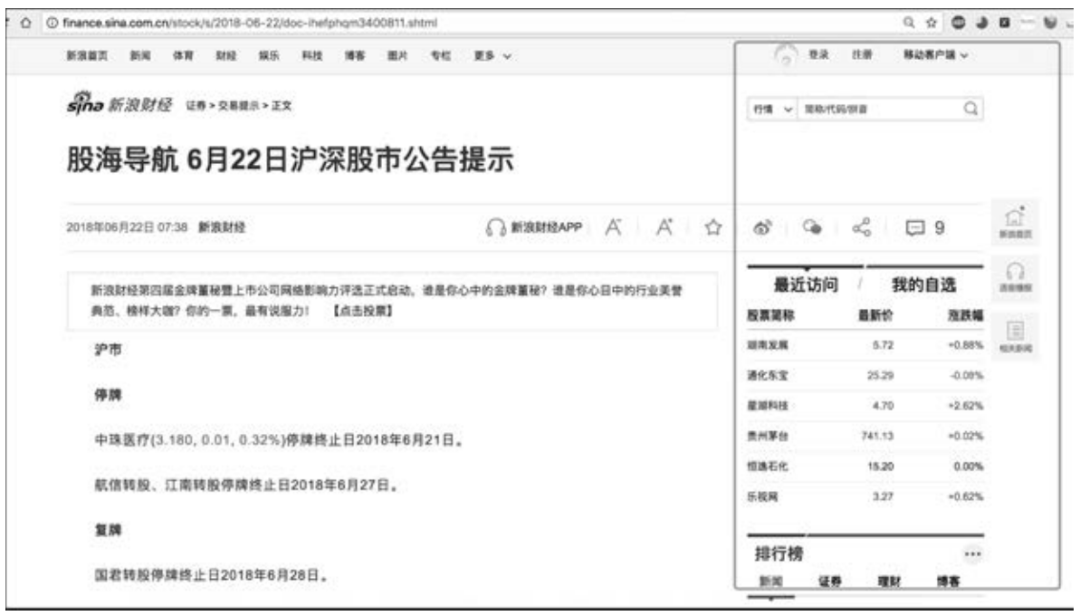
图6-2某只股票的一篇资讯页面
不过,用户很快就会发现,股票资讯文章页面中充斥着一些自己并不需要的广告或者新浪财经推送信息,为了去掉这些信息,可以使用BeautifulSoup中的decompose()方法去掉一个节点(该函数的作用是将当前节点移除文档树并完全销毁),接下来唯一要做的便是利用Chrome开发者工具分析并列出广告元素炒股配资网站,如图6-3所示。
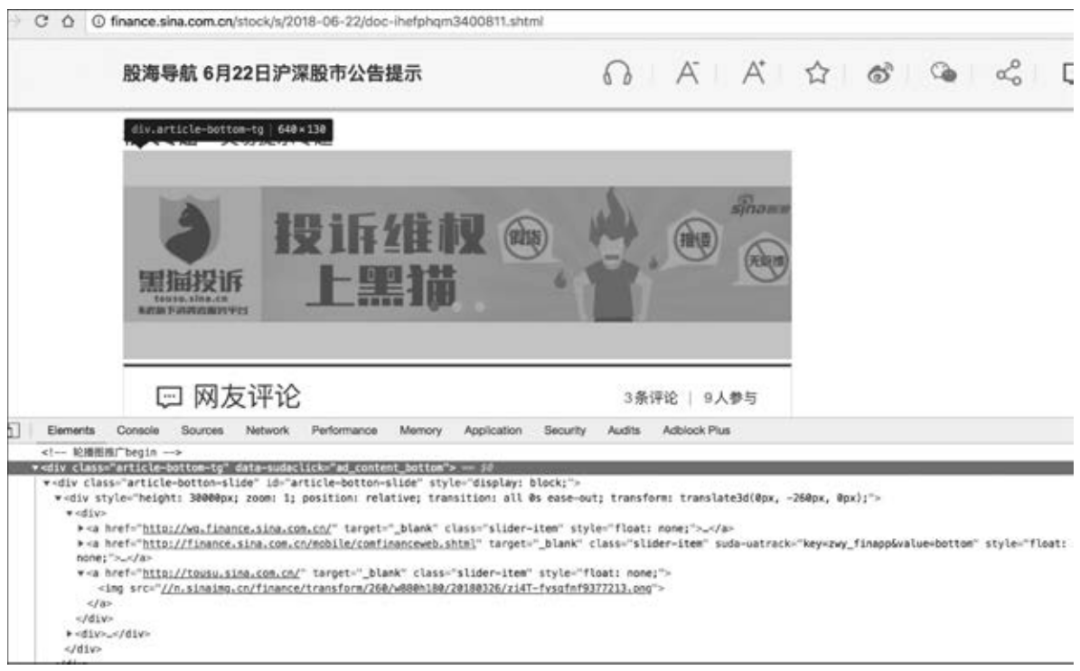
图6-3分析页面内容中的广告元素
经过上面的设计和分析,最终编写出实现爬取、清洗和保存网页这一流程的程序,见例6-1,语句的说明解释详见代码注释。
【例6-1】新浪财经新闻页面的爬取、清洗与保存。
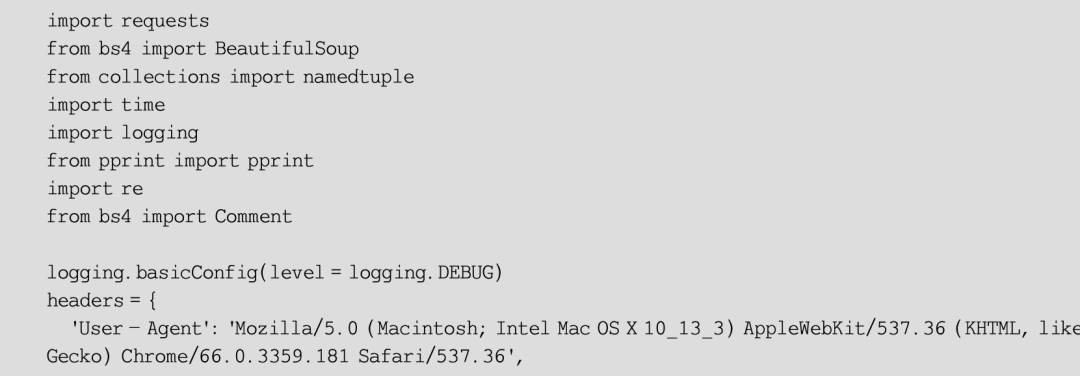
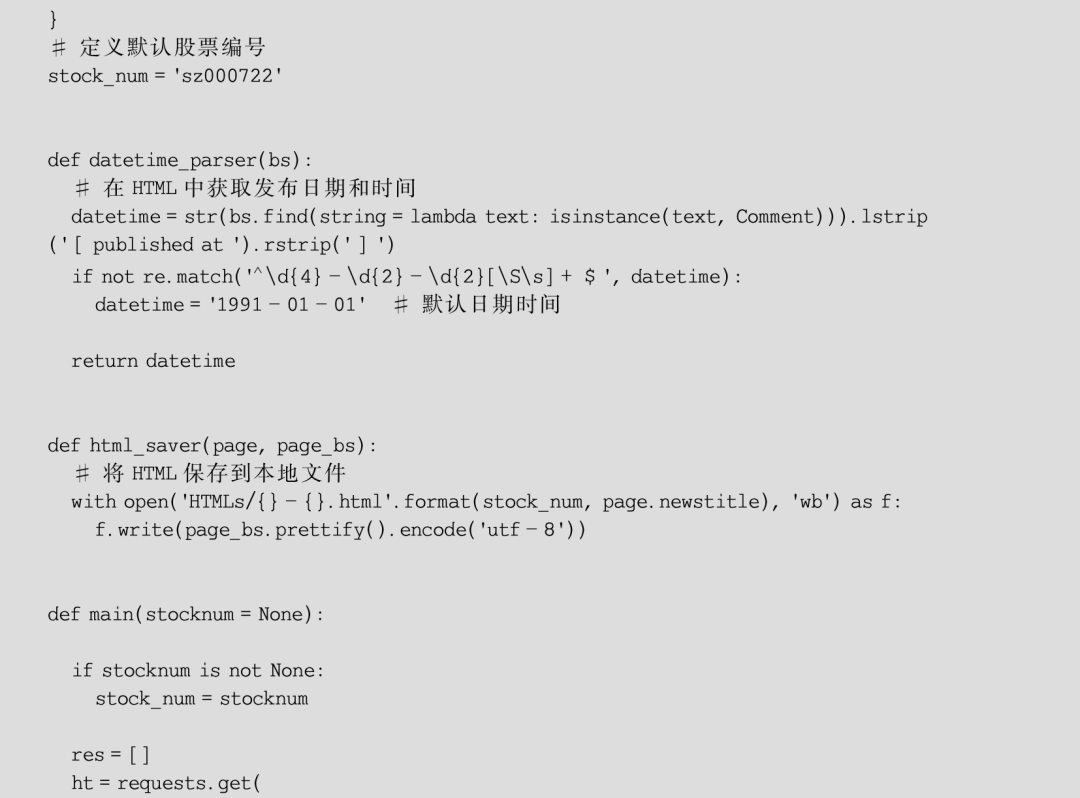
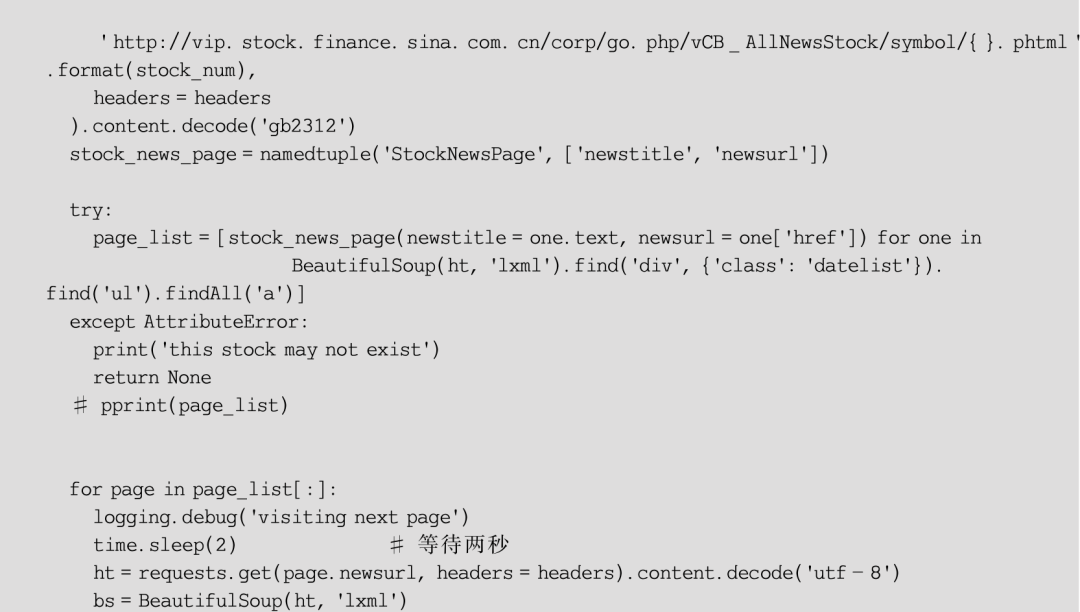



当然,这个程序还存在一些问题,主要有二,首先是在保存HTML内容到本地的过程中使用了相当原始的文件IO,实际上在大批量爬取时将HTML信息保存在数据库(如MongoDB)中是比较好的选择;其次配资网平台,在广告元素清洗的语句部分冗余较多,仍然存在很大的改进余地,可以考虑将待清洗元素规则统一保存到另一个文本文件中,通过一个读取函数进行加载。
02
运行并查看结果
运行上面的爬取程序,用户会看到控制台产生如图6-4所示的输出。
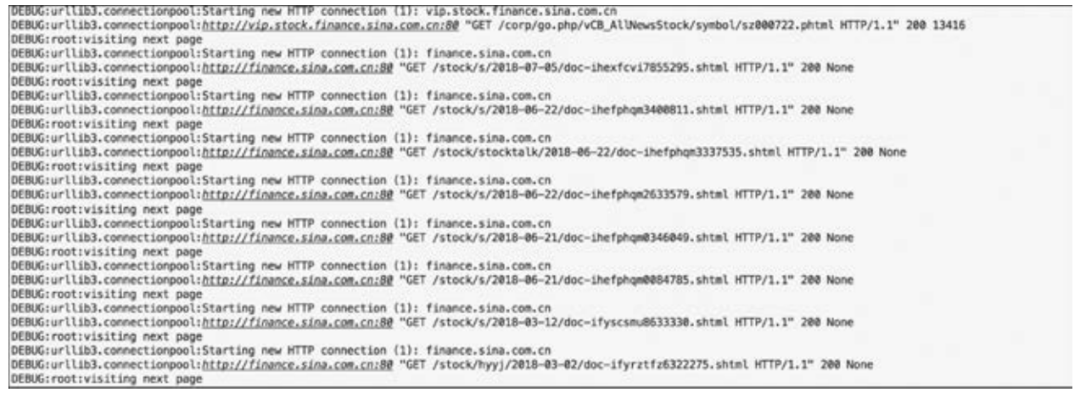
图6-4运行爬取程序后的输出
待程序运行结束后查看本地文件夹,可以看到HTML文件已经被批量保存下来,如图6-5所示。

图6-5本地文件夹中的HTML文件
想查看本案例完整内容欢迎购买《Python爬虫案例实战(微课视频版)》(ISBN:9787302633778)
03
参考书籍

↑点击图片官方旗舰店优惠购书↑
Python爬虫案例实战(微课视频版)
提供源码、380分钟视频,基础知识与丰富的Python爬虫实战案例相结合
吕云翔 韩延刚 张扬 主编
谢吉力 杨壮 王渌汀 王志鹏 杨瑞翌 副主编
定价:59.90元
ISBN:9787302633778
出版日期:2023.07.01
内容简介
本书将以Python语言为基础中国股票配资网,由浅入深地探讨网络爬虫技术,同时,通过具体的程序编写和实践来帮助读者了解和学习Python爬虫。
本书共包含20个案例,从内容上分为四部分,分别代表不同的爬虫阶段及场景,包括了Python爬虫编写的基础知识,以及对爬虫数据的存储、深入处理和分析。
第一部分爬虫基础篇。该部分简单介绍了爬虫的基本知识证券配资炒股,便于读者掌握相关知识,对爬虫有基本的认识。
第二部分实战基础篇(9个案例)。该部分既有简单、容易实现的入门案例,也有改进的进阶案例。丰富的内容包括爬虫常用的多种工具及方法,覆盖了爬虫的请求、解析、清洗、入库等全部常用流程,是入门实践的最佳选择。
第三部分框架应用篇(5个案例)。该部分内容从爬虫框架的角度出发,介绍了几个常用框架的案例,重点介绍了Scrapy框架,以及基于Python 3后的新特性的框架,如Gain和PySpider等,同时也对高并发应用场景下的异步爬虫做了案例解析,是不容错过的精彩内容。
第四部分爬虫应用场景及数据处理篇(6个案例)。该部分内容从实际应用的角度出发,通过不同的案例展示了爬虫爬取的数据的应用场景以及针对爬虫数据的数据分析,可以让读者体会到爬虫在不同场景上的应用,从另一个角度展示了爬虫的魅力,可以给读者带来一些新的思考。
这四部分由浅入深地介绍了爬虫常用的方法和工具,以及对爬虫数据处理的应用和实现。但需要注意的是,爬虫的技术栈不仅仅包含这几部分,而且在实际工作中的细分方法也不尽相同。本书只是对目前爬虫技术中最为常见的一些知识点,用案例的形式进行了分类和讲解,而更多的应用也值得读者在掌握一定的基础技能后进一步探索。